
In my previous article, I explained the two different types of variable types in C# – value types and reference types. Hopefully you remember how I explained that value types deal with raw data manipulation, while reference type variables deal with references to data elsewhere of the computer.
I also mentioned that making a value type variable null would affect the data it was storing directly, while making a reference type null would only make that variable stop pointing to the section of memory it was originally associated with, but it wouldn’t affect that data itself.
I also explained the concept with this diagram:

The Devil in the Details
If you were really paying attention to my first article, you might have noticed that throughout the whole masterpiece (just havin’ a little fun here) I never really mentioned the memory structures that actually formed the foundation behind value and reference types. I always said that value types and references are stored “in memory” while the stuff that reference types point to are stored “somewhere else.” Did you ever wonder where they were actually stored?
The Culprits
So in C#, there are two memory structures behind data storage during execution of threads. The first is called the stack and the second is called the heap.
It can be pretty difficult to explain the stack and heap properly if start by explaining them separately, so I’ll have to explain them simultaneously for a little bit first.
A very beneficial way to understand the difference between the stack and the heap would be understanding scope. We all know that some variables are limited in scope to the methods in which they were created (local variables) while other variables are somewhat global variables to the class in which they were made (they can be accessed anywhere within the class and have a universal scope). These variables are called instance variables.
It’s useful to associate the heap with that universal scope property. Variables that can be accessed at any time within their parent class or struct, or externally by other classes or structs are variables stored in the heap. The heap has no dimension of scope to limit the accessibility of the variables it keeps. Access modifiers like public and private may limit their accessibility form external objects, but the variables still have a global scope in their parents and hence are still stored in the heap. Static variables are also stored in the heap too—I’m sure you can understand why.
Local variables, however, are stored in the stack. Any variable or struct called within a method is stored in the stack. Why? You can tell because of its limited scope. Nothing outside that method can access those variables, because those variables only exist in that method’s little world. Once that method is terminated, all those variables are destroyed.
This principle holds true for reference type variables too.
For reference type variables, the information they point to is always stored in the heap. The references themselves though, can either be stored in the stack or the heap. The variable can be stored in the stack if it’s a local variable, or stored in the heap if it’s an instance or static variable.
The Nature of the Stack
So we’ve established that in the following code:
class exampleClass
{
char a;
int b;
void aMethod()
{
int c;
}
}
…variables a and b would be stored in the heap while variable c would be stored in the stack.
But what exactly is the stack?
The stack is the memory structure that threads use for execution. Every operating thread has its own stack. However, a program is only allocated one heap, a heap that each thread would have access to and shares with other threads. So do illustrate this, presume a programmer has a program with 4 independent threads working simultaneously. It’d look a little like this:

So where does the dimension of scope come into stacks?
From this diagram I think you can already see why different threads can’t access the local variables of other threads. There’s simply no link between the two. They only have a link to the heap, and that’s it.
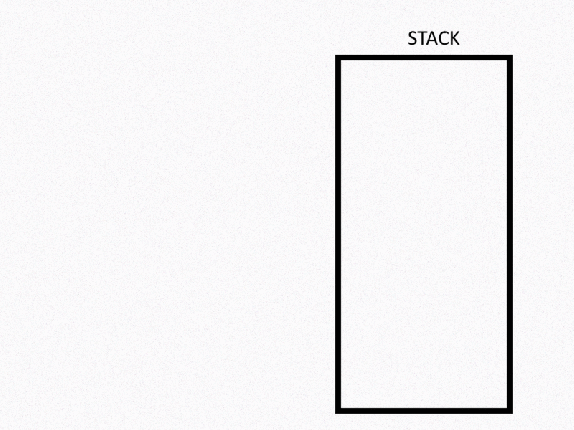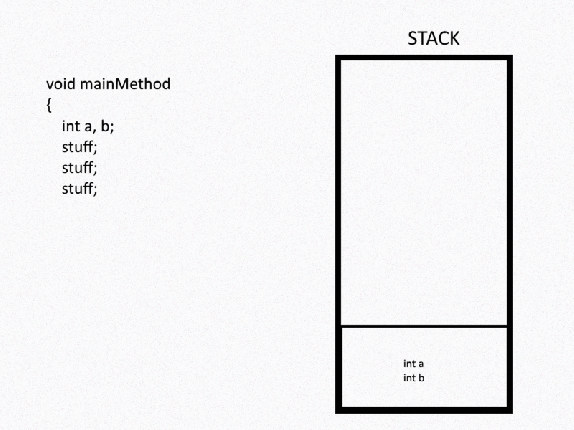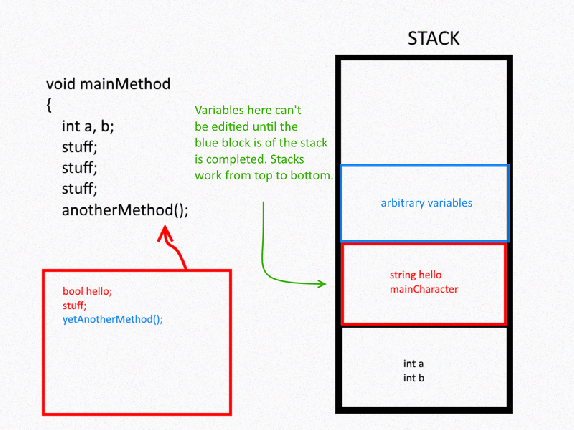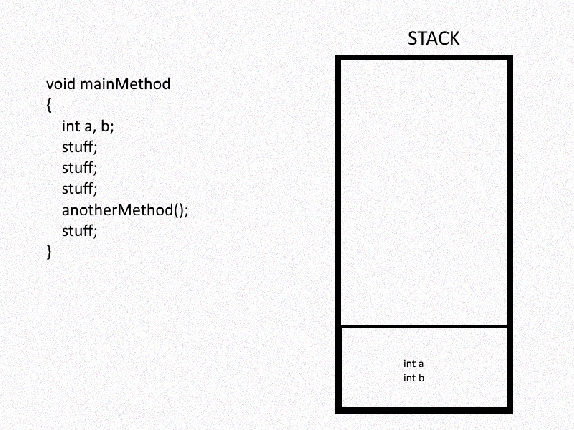
But say you had a thread that was operating a method, and within that method another method is called. No variables within the parent method are accessible to the child method unless they are explicitly made available as parameters. Why?
 To understand this, think of stack memory as a very busy accountant. All day he works away at this stack of paperwork he has on his desk. Now imagine he’s in the middle of working on a stack of paperwork called methodA. While he’s in the middle of working on that stack, his boss shows up and slams a fresh new stack called methodB right on top of the stack that this poor accountant wasn’t even finished working on. He now has to finish working on methodB before he can continue work on methodA. Any information he wants from methodA is blocked by the method (since methodA is underneath methodB).
To understand this, think of stack memory as a very busy accountant. All day he works away at this stack of paperwork he has on his desk. Now imagine he’s in the middle of working on a stack of paperwork called methodA. While he’s in the middle of working on that stack, his boss shows up and slams a fresh new stack called methodB right on top of the stack that this poor accountant wasn’t even finished working on. He now has to finish working on methodB before he can continue work on methodA. Any information he wants from methodA is blocked by the method (since methodA is underneath methodB).
This is why scope exists. It’s because of this top-to-bottom nature of the stack. As many other programmers would term it, stack is LIFO (last in, first out). Each method has a block where its data is stored, and they are layered on top of each other in a manner in which new blocks fall on top of older ones and blocks them out.
The Heap
The heap however, doesn’t have this order of organization. It’s just a disorganized hodgepodge repository of data. There’s no restriction that new data puts on the accessibility of older data. That’s why at any point, data from the heap is accessible and the scope is somewhat universal. Every stack has access to the heap and there’s no blockage of data.
Time to clean up
 An interesting concept comes into existence due to this disorganized nature of the heap.
An interesting concept comes into existence due to this disorganized nature of the heap.
Have you ever heard the term garbage collection before? It’s a term used all the time over sites like StackOverflow.com.
Garbage collection actually has to do with heap data.
You see, in the stack, data is destroyed when the memory block currently being operated on is terminated. Upon termination, the block and all its associated variables are deleted.
But something like that can’t happen in the heap. There’s little organization in the heap, so the computer doesn’t really know for sure when to delete data from it.
So computers that run languages like C# have something called the garbage collector. What the garbage collector does is periodically search the heap for data that no longer has variables or references pointing to it. Such data is permanently inaccessible to any program and is, in a sense, just lost in heap; so the garbage collector goes ahead and deletes it.
Signing off!
Phew! That wasn’t an easy post!
This thing took my over 5 different articles and StackOverflow pages (plus a video) to understand. Interestingly, none of them explained it in terms of scope, yet I find that by far the easiest way to conceptualize this.
But the video I watched was pretty cool too, so here it is as a bonus:
https://www.youtube.com/watch?v=_8-ht2AKyH4
So I suppose that’s it! I hope you’ve taken something new from this as I have.
See you next fortnight.
Image credit: Freepik.com among others



{kind=link}